Netflix год спустя
Ровно год назад я запостил анонс конкурса Netflix. Пришло время подвести промежуточные итоги.
Напомню, что 1 октября прошлого года компания Netflix, которая дает напрокат DVD по почте, объявила соревнование на лучший алгоритм машинного обучения. Условия конкурсы сравнительно просты - компания публикует базу данных, содержащую около ста миллионов рейтингов, которые полмиллиона зрителей за несколько лет выставили восемнадцати тысячам фильмам. Задача состоит в том, чтобы на основе этих данных как можно точнее предсказать рейтинги, отсутствующие в этой базе данных, но известные Нетфликсу. Критерий сравнения алгоритмов - среднеквадратичная ошибка на 3,5 миллионах рейтингов, которые необходимо угадать.
Главный приз в один миллион долларов достанется тому, кто сможет побить (секретный) алгоритм Нетфликса под названием Cinematch на 10%. Для сравнения: если для пары зритель-фильм игнорировать рейтинги, выставленные зрителем, и просто угадывать средний рейтинг фильма, то среднеквадратичная ошибка составит приблизительно 1.05 (рейтинги в базе данных - целые числа от 1 до 5, догадка может быть вещественным числом), что на 10% больше, чем ошибка Cinematch. Если при этом еще учитывать и рейтинг пользователя, то можно подобраться к алгоритму Нетфликса на расстояние +4%.
Поскольку каждое последующее улучшение дается всё с большим трудом, то легко представить, что специалисты Нетфликса подумали, что задача превзойти их алгоритм на 10% сравнима по сложности с проблемой P≠NP, тоже оцененной в $1 млн. Для того, чтобы дать стимулы работать над задачей, даже при том, что большой приз получить, по их представлениям, нереально, были учреждены промежуточные призы размером в пятьдесят тысяч долларов. Чтобы выиграть промежуточный приз, достаточно в течение года улучшить прошлогодний результат на 1% (в первый год соревнования за базовый принят результат Cinematch).
Соревнования организовано максимально просто и открыто - чтобы принять в нём участие, достаточно скачать базу данных рейтингов, разобраться в формате ответа, и закачать файл из 3,5 миллионов угаданных рейтингов на сервер. Результат станет известен через несколько минут. За лучшими результатами можно следить он-лайн.
Резонанс, вызванный соревнованием, превзошел все ожидания. Хотя точное количество участников оценить сложно (команды могли регистрироваться в произвольных составах и неограниченное количество раз), оно измеряется многими тысячами. Что касается результатов, показанных командами, то они оказались много лучше ожиданий Нетфликса.
Первый претендент на промежуточный приз, с результатом в -1% к ошибке Cinematch, появился через неделю после начала соревнования. Спустя три недели Cinematch был побит на -4,5%, еще через месяц был преодолен рубеж -5%. К началу декабря Cinematch был превзойден на 6%. В этот момент стороннему наблюдателю могло показаться, что миллион долларов не за горами.
До появления на доске результатов -7% пришлось ждать пять месяцев, а дальше дело, казалось, совсем уж застопорилось. Здесь мы прервемся, чтобы вкратце описать основные методы, которыми пользовались участники.
Малоранговое приближение. Начнем с интуиции. Легко поверить в то, что оценка зрителем фильма определяется в первом приближении не очень большим числом параметров: насколько данный фильм соответствует жанрам, любимым зрителем; понимает ли зритель язык, на котором снят фильм; кому-то нравятся черно-белые фильмы, кто-то не любит фильмы с определенными тематическими элементами и пр. Хочется думать, что можно с достаточной точностью описать фильм и зрительские предпочтения вектором из 20-100 элементов, и использовать скалярное произведение этих двух векторов как поправку к среднему рейтингу фильма и средней оценке зрителя. Иными словами, если исходная матрица оценок M размером 18000×500000, большая часть значений в которой нам не известна, то мы хотим найти её приближение в виде произведения двух матриц U и V размерностей 18000×k и k×500000 для некоторого сравнительного небольшого k. Для задания метрики имеет смысл выбрать норму Фробениуса, которая есть та самая среднеквадратичная ошибка, которую мы хотим минимизировать.
Часть характеристик фильмов можно попытаться угадать и ввести вручную - номинация на Оскара или наличие фестивальных призов, год выпуска, MPAA-рейтинг (G, PG, PG-13, R, NC-17) и так далее. Процесс этот трудоемкий (в исходной базе данных наличествуют только название фильма и год выхода на экран) и с неочевидным результатом. Гораздо более естественным подходом была бы попытка найти произвольные матрицы малой размерности, чье произведение аппроксимирует известную нам часть M.
Весьма простой алгоритм, реализующий этот подход, укладывается в несколько десятков строк на C и позволяет побить Cinematch на 5%. Подробнее о нем можно прочесть в статье, написанной венгерскими авторами из команды Gravity, одного из лидеров соревнования.
Ближайшие соседи. Кардинально отличающийся от предыдущего подход состоит в попытке определить фильмы, “похожие” друг на друга. Под “похожестью” удобно определить высокую степень корреляции рейтингов, поскольку только рейтинги нас и заботят. Тогда, если перед нами стоит задача угадать рейтинг, выставленный зрителем фильму A, мы найдем среди фильмов, уже посмотренных этим зрителем, похожие на A. После этого мы попытаемся угадать по рейтингам этих фильмов рейтинг A.
Вот иллюстрация того, насколько корреляция рейтингов соответствует тому, что мы можем назвать сходством фильмов. В колонках таблицы перечислены (в порядке убывания коэффициента корреляции, с поправкой на количество общих рейтингов) самые близкие фильмы к Pulp Fiction и Gone with the Wind соответственно.
Pulp Fiction (1994)Gone with the Wind (1939)
Pulp Fiction: Bonus Material (1994)
Plump Fiction (1996)
Reservoir Dogs (1992)
Punch-Drunk Love (2002)
American Beauty (1999)
A Clockwork Orange (1971)
Kill Bill: Vol. 1 (2003)
The Royal Tenenbaums (2001)
Fight Club (1999)
Sin City (2005)
Natural Born Killers (1994)
Memento (2000)
Kill Bill: Vol. 2 (2004)
Apocalypse Now (1979)
Magnolia (1999)
Being John Malkovich (1999)
Oldboy (2003)
Eternal Sunshine of the Spotless Mind (2004)
Lost in Translation (2003)It's a Wonderful Life (1946)
A Star Is Born (1954)
The Yearling (1946)
A Star Is Born (1937)
The Sound of Music (1965)
Oklahoma! (1955)
Show Boat (1951)
Doctor Zhivago (2002)
The King and I (1956)
The Bells of St. Mary's (1945)
Ben-Hur (1959)
Miracle on 34th Street (1947)
Little Women (1932)
The Ten Commandments (1956)
The Thorn Birds (1983)
Giant (1956)
Doctor Zhivago (1965)
West Side Story (1961)
The Wizard of Oz (1939)
Оказывается, что способ определения похожих фильмов имеет значение сильно меньшее, чем второй шаг алгоритма - восстановление отсутствующего рейтинга по рейтингам, выставленным похожим фильмам. Интересный и, главное, простой способ интерполяции этого рейтинга описан в статье другого лидера соревнования - команды BellKor. Имплементация их метода длиной в две сотни строк улучшает Cinematch на... все те же 5%. По сообщению Нетфликса сам Cinematch тоже принадлежит этому же семейству алгоритмов.
Кстати, команда BellKor долгое время была загадочным анонимом для остальных участников. На специальном семинаре, приуроченом к KDD'07, страна узнала своих героев - Роберта Белла и Эхуда Корена, работающих в AT&T Labs - сестре Bellcore.
Конечно, подходов, опробованных участниками, гораздо больше. Успешные команды, без сомнения, реализовали все стандартные алгоритмы. И причина этого не в том, что не испытав на практике алгоритм, ни один серьезный участник не станет его отбрасывать. На самом деле, комбинация рейтингов, предсказанных разными методами, как правило, оказывается точнее, чем любой из этих методов по отдельности.
Итак, мы остановились на том, что к апрелю этого года базовый алгоритм был превзойден на 7%. К концу сентября наверху таблицы надежно закрепилась команда BellKor, которой наконец покорились 8%, с отрывом от ближайшего конкурента - венгров из Gravity - на почти 0,5%. Тут следует описать подробнее правила конкурса.
Наряду с базой рейтингов Нетфликс предоставляет два файла: тестовый набор заданий, ответы на которые в базе есть, и собственно задание. Оно, в свою очередь, секретным образом поделено пополам на две части. Результат (корень из среднеквадратичного отклонения от известных только Нетфликсу рейтингов) присланного варианта ответа публикуется только для одной половины. Приз будет присуждаться по результатам на той части задания, которые команды никогда не видели. Зачем это сделано? Во-первых, задание не есть случайная выборка из базы рейтингов. Вместо этого она содержит непропорционально много недавно вышедших фильмов, поскольку это именно та область, где, по мнению Нетфликса, его рекомендации наиболее интересны. Поэтому тестовый набор, выбранный при помощи такого же алгоритма, позволяет командам тестировать себя, фактически не прибегая к помощи сервера. По опыту команд, разница между результатом на задании и на тестовом наборе, как правило, находится в пределе одной-двух десятых долей процента.
Во-вторых, задание поделено на часть, на которой результат сообщается, и на часть, на которой результат остается секретным, для того, чтобы предотвратить команды от победы в конкурсе за счет решения задачи машинного обучения в приложении к секретным рейтингам. Действительно, если бы опубликованный результат подсчитывался по всему заданию, на основе достаточного числа ответов сервера теоретически возможно было бы выяснить все или, по крайней мере, немалую часть секретных рейтингов.
Поскольку команды могли позволить себе не анонсировать публично свои достижения, ожидалось, что к концу года за первое место (за которое обещаны 50 тыс. долларов, изрядно, впрочем, похудевшие за год относительно мировых валют) может развернуться борьба. Так как ни одна из команд по отдельности не могла приблизиться к результату BellKor, две команды, Gravity и Dinosaur Planet пошли на альянс. За несколько часов до завершения первого года соревнования они смикшировали свои результаты и сравнялись с BellKor, одним прыжком преодолев разрыв. Раз приз будет присужден на основании секретной части задания, победа фактически определялась бы подбрасыванием монеты. В ответ на это BellKor расширили свой состав, включив в него своего коллегу Криса Волински, и оторвались от преследователей на 0.05%. Могу предположить, что Волински сам ранее работал над проблемой, и в последний момент его результаты были скомбинированы с BellKor. Объединенная команда была названа KorBell и в ночь подведения итогов ссылка с названия команды вела на сайт марки шампанского.
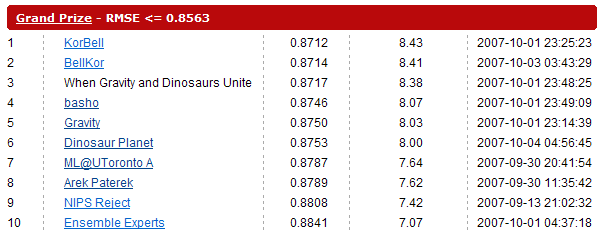
Некоторая неопределенность с победителем всё еще остается: во-первых, еще не объявлены результаты на секретной части задания, во-вторых, неясно, пойдут ли AT&T Labs на условия, необходимые для получения приза (публикация алгоритма и предоставление Нетфликсу лицензии на его использование).
Еще остается одна загадка: если бы инженеры Нетфликс чуть лучше разбирались в области collaborative filtering, и ошибка алгоритма Cinematch был бы меньше всего на два-три процента, то я думаю, сейчас было бы ясно, что большой приз никогда не будет выплачен. Если бы инженеры были чуть-чуть глупее, то конкурс завершился бы уже в этом году. Однако Cinematch оказался в той узкой области, что команды-лидеры уже настолько близки к победе, что у них еще есть шансы, но всё же достаточно далеки, что понятно, что им требуется еще, по меньшей мере, одна хорошая идея.
Напомню, что 1 октября прошлого года компания Netflix, которая дает напрокат DVD по почте, объявила соревнование на лучший алгоритм машинного обучения. Условия конкурсы сравнительно просты - компания публикует базу данных, содержащую около ста миллионов рейтингов, которые полмиллиона зрителей за несколько лет выставили восемнадцати тысячам фильмам. Задача состоит в том, чтобы на основе этих данных как можно точнее предсказать рейтинги, отсутствующие в этой базе данных, но известные Нетфликсу. Критерий сравнения алгоритмов - среднеквадратичная ошибка на 3,5 миллионах рейтингов, которые необходимо угадать.
Главный приз в один миллион долларов достанется тому, кто сможет побить (секретный) алгоритм Нетфликса под названием Cinematch на 10%. Для сравнения: если для пары зритель-фильм игнорировать рейтинги, выставленные зрителем, и просто угадывать средний рейтинг фильма, то среднеквадратичная ошибка составит приблизительно 1.05 (рейтинги в базе данных - целые числа от 1 до 5, догадка может быть вещественным числом), что на 10% больше, чем ошибка Cinematch. Если при этом еще учитывать и рейтинг пользователя, то можно подобраться к алгоритму Нетфликса на расстояние +4%.
Поскольку каждое последующее улучшение дается всё с большим трудом, то легко представить, что специалисты Нетфликса подумали, что задача превзойти их алгоритм на 10% сравнима по сложности с проблемой P≠NP, тоже оцененной в $1 млн. Для того, чтобы дать стимулы работать над задачей, даже при том, что большой приз получить, по их представлениям, нереально, были учреждены промежуточные призы размером в пятьдесят тысяч долларов. Чтобы выиграть промежуточный приз, достаточно в течение года улучшить прошлогодний результат на 1% (в первый год соревнования за базовый принят результат Cinematch).
Соревнования организовано максимально просто и открыто - чтобы принять в нём участие, достаточно скачать базу данных рейтингов, разобраться в формате ответа, и закачать файл из 3,5 миллионов угаданных рейтингов на сервер. Результат станет известен через несколько минут. За лучшими результатами можно следить он-лайн.
Резонанс, вызванный соревнованием, превзошел все ожидания. Хотя точное количество участников оценить сложно (команды могли регистрироваться в произвольных составах и неограниченное количество раз), оно измеряется многими тысячами. Что касается результатов, показанных командами, то они оказались много лучше ожиданий Нетфликса.
Первый претендент на промежуточный приз, с результатом в -1% к ошибке Cinematch, появился через неделю после начала соревнования. Спустя три недели Cinematch был побит на -4,5%, еще через месяц был преодолен рубеж -5%. К началу декабря Cinematch был превзойден на 6%. В этот момент стороннему наблюдателю могло показаться, что миллион долларов не за горами.
До появления на доске результатов -7% пришлось ждать пять месяцев, а дальше дело, казалось, совсем уж застопорилось. Здесь мы прервемся, чтобы вкратце описать основные методы, которыми пользовались участники.
Малоранговое приближение. Начнем с интуиции. Легко поверить в то, что оценка зрителем фильма определяется в первом приближении не очень большим числом параметров: насколько данный фильм соответствует жанрам, любимым зрителем; понимает ли зритель язык, на котором снят фильм; кому-то нравятся черно-белые фильмы, кто-то не любит фильмы с определенными тематическими элементами и пр. Хочется думать, что можно с достаточной точностью описать фильм и зрительские предпочтения вектором из 20-100 элементов, и использовать скалярное произведение этих двух векторов как поправку к среднему рейтингу фильма и средней оценке зрителя. Иными словами, если исходная матрица оценок M размером 18000×500000, большая часть значений в которой нам не известна, то мы хотим найти её приближение в виде произведения двух матриц U и V размерностей 18000×k и k×500000 для некоторого сравнительного небольшого k. Для задания метрики имеет смысл выбрать норму Фробениуса, которая есть та самая среднеквадратичная ошибка, которую мы хотим минимизировать.
Часть характеристик фильмов можно попытаться угадать и ввести вручную - номинация на Оскара или наличие фестивальных призов, год выпуска, MPAA-рейтинг (G, PG, PG-13, R, NC-17) и так далее. Процесс этот трудоемкий (в исходной базе данных наличествуют только название фильма и год выхода на экран) и с неочевидным результатом. Гораздо более естественным подходом была бы попытка найти произвольные матрицы малой размерности, чье произведение аппроксимирует известную нам часть M.
Весьма простой алгоритм, реализующий этот подход, укладывается в несколько десятков строк на C и позволяет побить Cinematch на 5%. Подробнее о нем можно прочесть в статье, написанной венгерскими авторами из команды Gravity, одного из лидеров соревнования.
Ближайшие соседи. Кардинально отличающийся от предыдущего подход состоит в попытке определить фильмы, “похожие” друг на друга. Под “похожестью” удобно определить высокую степень корреляции рейтингов, поскольку только рейтинги нас и заботят. Тогда, если перед нами стоит задача угадать рейтинг, выставленный зрителем фильму A, мы найдем среди фильмов, уже посмотренных этим зрителем, похожие на A. После этого мы попытаемся угадать по рейтингам этих фильмов рейтинг A.
Вот иллюстрация того, насколько корреляция рейтингов соответствует тому, что мы можем назвать сходством фильмов. В колонках таблицы перечислены (в порядке убывания коэффициента корреляции, с поправкой на количество общих рейтингов) самые близкие фильмы к Pulp Fiction и Gone with the Wind соответственно.
Pulp Fiction (1994)Gone with the Wind (1939)
Pulp Fiction: Bonus Material (1994)
Plump Fiction (1996)
Reservoir Dogs (1992)
Punch-Drunk Love (2002)
American Beauty (1999)
A Clockwork Orange (1971)
Kill Bill: Vol. 1 (2003)
The Royal Tenenbaums (2001)
Fight Club (1999)
Sin City (2005)
Natural Born Killers (1994)
Memento (2000)
Kill Bill: Vol. 2 (2004)
Apocalypse Now (1979)
Magnolia (1999)
Being John Malkovich (1999)
Oldboy (2003)
Eternal Sunshine of the Spotless Mind (2004)
Lost in Translation (2003)It's a Wonderful Life (1946)
A Star Is Born (1954)
The Yearling (1946)
A Star Is Born (1937)
The Sound of Music (1965)
Oklahoma! (1955)
Show Boat (1951)
Doctor Zhivago (2002)
The King and I (1956)
The Bells of St. Mary's (1945)
Ben-Hur (1959)
Miracle on 34th Street (1947)
Little Women (1932)
The Ten Commandments (1956)
The Thorn Birds (1983)
Giant (1956)
Doctor Zhivago (1965)
West Side Story (1961)
The Wizard of Oz (1939)
Оказывается, что способ определения похожих фильмов имеет значение сильно меньшее, чем второй шаг алгоритма - восстановление отсутствующего рейтинга по рейтингам, выставленным похожим фильмам. Интересный и, главное, простой способ интерполяции этого рейтинга описан в статье другого лидера соревнования - команды BellKor. Имплементация их метода длиной в две сотни строк улучшает Cinematch на... все те же 5%. По сообщению Нетфликса сам Cinematch тоже принадлежит этому же семейству алгоритмов.
Кстати, команда BellKor долгое время была загадочным анонимом для остальных участников. На специальном семинаре, приуроченом к KDD'07, страна узнала своих героев - Роберта Белла и Эхуда Корена, работающих в AT&T Labs - сестре Bellcore.
Конечно, подходов, опробованных участниками, гораздо больше. Успешные команды, без сомнения, реализовали все стандартные алгоритмы. И причина этого не в том, что не испытав на практике алгоритм, ни один серьезный участник не станет его отбрасывать. На самом деле, комбинация рейтингов, предсказанных разными методами, как правило, оказывается точнее, чем любой из этих методов по отдельности.
Итак, мы остановились на том, что к апрелю этого года базовый алгоритм был превзойден на 7%. К концу сентября наверху таблицы надежно закрепилась команда BellKor, которой наконец покорились 8%, с отрывом от ближайшего конкурента - венгров из Gravity - на почти 0,5%. Тут следует описать подробнее правила конкурса.
Наряду с базой рейтингов Нетфликс предоставляет два файла: тестовый набор заданий, ответы на которые в базе есть, и собственно задание. Оно, в свою очередь, секретным образом поделено пополам на две части. Результат (корень из среднеквадратичного отклонения от известных только Нетфликсу рейтингов) присланного варианта ответа публикуется только для одной половины. Приз будет присуждаться по результатам на той части задания, которые команды никогда не видели. Зачем это сделано? Во-первых, задание не есть случайная выборка из базы рейтингов. Вместо этого она содержит непропорционально много недавно вышедших фильмов, поскольку это именно та область, где, по мнению Нетфликса, его рекомендации наиболее интересны. Поэтому тестовый набор, выбранный при помощи такого же алгоритма, позволяет командам тестировать себя, фактически не прибегая к помощи сервера. По опыту команд, разница между результатом на задании и на тестовом наборе, как правило, находится в пределе одной-двух десятых долей процента.
Во-вторых, задание поделено на часть, на которой результат сообщается, и на часть, на которой результат остается секретным, для того, чтобы предотвратить команды от победы в конкурсе за счет решения задачи машинного обучения в приложении к секретным рейтингам. Действительно, если бы опубликованный результат подсчитывался по всему заданию, на основе достаточного числа ответов сервера теоретически возможно было бы выяснить все или, по крайней мере, немалую часть секретных рейтингов.
Поскольку команды могли позволить себе не анонсировать публично свои достижения, ожидалось, что к концу года за первое место (за которое обещаны 50 тыс. долларов, изрядно, впрочем, похудевшие за год относительно мировых валют) может развернуться борьба. Так как ни одна из команд по отдельности не могла приблизиться к результату BellKor, две команды, Gravity и Dinosaur Planet пошли на альянс. За несколько часов до завершения первого года соревнования они смикшировали свои результаты и сравнялись с BellKor, одним прыжком преодолев разрыв. Раз приз будет присужден на основании секретной части задания, победа фактически определялась бы подбрасыванием монеты. В ответ на это BellKor расширили свой состав, включив в него своего коллегу Криса Волински, и оторвались от преследователей на 0.05%. Могу предположить, что Волински сам ранее работал над проблемой, и в последний момент его результаты были скомбинированы с BellKor. Объединенная команда была названа KorBell и в ночь подведения итогов ссылка с названия команды вела на сайт марки шампанского.
Некоторая неопределенность с победителем всё еще остается: во-первых, еще не объявлены результаты на секретной части задания, во-вторых, неясно, пойдут ли AT&T Labs на условия, необходимые для получения приза (публикация алгоритма и предоставление Нетфликсу лицензии на его использование).
Еще остается одна загадка: если бы инженеры Нетфликс чуть лучше разбирались в области collaborative filtering, и ошибка алгоритма Cinematch был бы меньше всего на два-три процента, то я думаю, сейчас было бы ясно, что большой приз никогда не будет выплачен. Если бы инженеры были чуть-чуть глупее, то конкурс завершился бы уже в этом году. Однако Cinematch оказался в той узкой области, что команды-лидеры уже настолько близки к победе, что у них еще есть шансы, но всё же достаточно далеки, что понятно, что им требуется еще, по меньшей мере, одна хорошая идея.