Выгрузка лога PostgreSQL из облака AWS - часть 1.
Или немного прикладной тетрисологии.
Всё новое- хорошо забытое старое.
Эпиграфы

Постановка задачи
Необходимо периодически загружать текущий лог-файл PostgreSQL из облака AWS на локальный Linux хост. Не в реальном времени, но, скажем так, с небольшой задержкой.
Период загрузки обновления лог-файла - 5 минут.
Лог-файл, в AWS, ротируется каждый час.
Используемые инструменты
Для загрузки лог-файла на хост используется bash-скрипт, вызывающий AWS API «aws rds download-db-log-file-portion».
Параметры
- --db-instance-identifier: Имя инстанса в AWS;
- --log-file-name: имя текущего сформированного лог-файла
- --max-item: Общее количество элементов, возвращаемых в выходных данных команды.Размер порции загружаемого файла.
- --starting-token: Метка начальной порции
Да и просто - интересная задача, для тренировки и разнообразия в ходе рабочего времени.
Предположу, что задача в силу обыденности уже решена. Но быстрый гугл решений не подсказал, а искать более углубленно не было особого желания. В любом случае - неплохая тренировка.
Формализация задачи
Конечный лог-файл представляет собой множество строк переменной длины. Графически, лог-файл можно представить, примерно так:

Уже что-то напоминает? При чём тут «тетрис»? А вот, при чем.
Если представить возможные варианты, возникающие при загрузке очередного файла графически (для простоты, в данном случае, пусть строки имеют одну длину), получатся стандартные фигуры тетриса:
1) Файл загружен целиком и является конечным. Размер порции больше размера конечного файла:

2) Файл имеет продолжение. Размер порции меньше размера конечного файла:
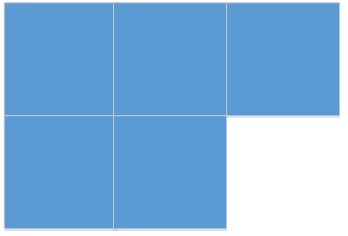
3) Файл является продолжением предыдущего файла и имеет продолжение. Размер порции меньше размера остатка конечного файла:
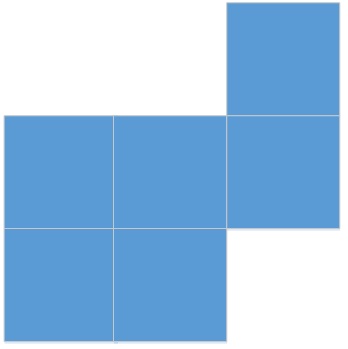
4) Файл является продолжением предыдущего файла и является конечным. Размер порции больше размера остатка конечного файла:
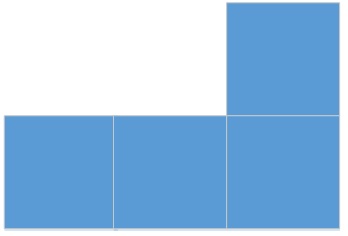
Задача - собрать прямоугольник или поиграть в тетрис, на новом уровне.

Проблемы, возникающие по ходу решения задачи
1) Склеить строку из 2-х порций
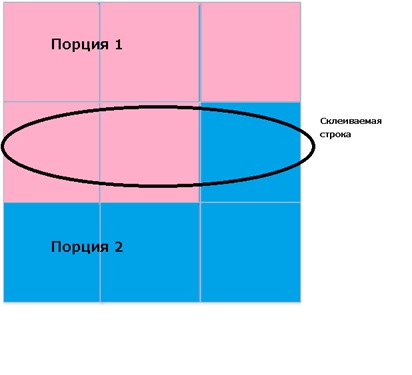
В общем-то никаких особых проблем не возникло. Стандартная задача из начального курса программирования.
Оптимальный размер порции
А вот это, несколько интереснее.
К сожалению, нет возможности использовать смещение после метки начальной порции:
As you already know the option --starting-token is used to specify where to start paginating. This option takes String values which would mean that if you try to add an offset value in front of the Next Token string, the option will not be taken into consideration as an offset.
И поэтому, приходится читать кусками-порциями.
Если читать большими порциями, то количество чтений будет минимальным, но объем будет максимальным.
Если читать маленькими порциями, то наоборот, количество чтений будет максимальным, но зато объем будет минимальным.
Поэтому, для сокращения трафика и для общей красоты решения, пришлось придумать некое решение, к сожалению, немного смахивающее на костыль.
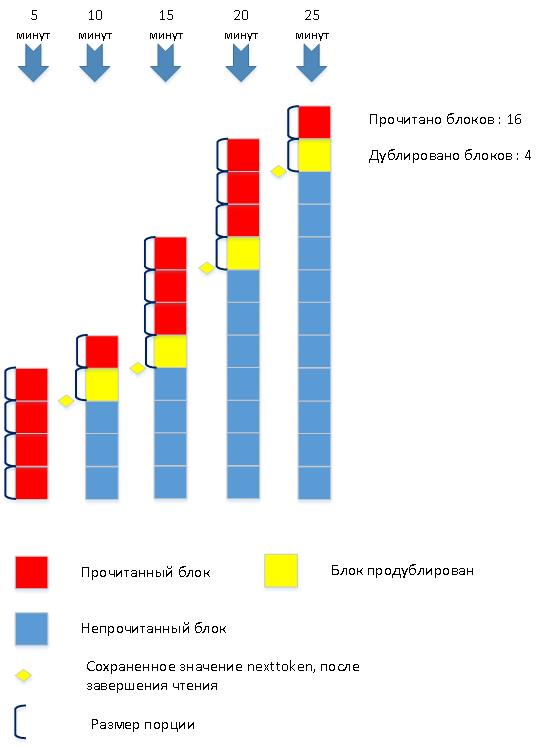
Для иллюстрации, рассмотрим процесс загрузки лог-файла в 2-х сильно упрощенных вариантах. Количество чтений в обоих случаях зависит от размера порции.
1) Загружаем малыми порциями:
2) Загружаем большими порциями:
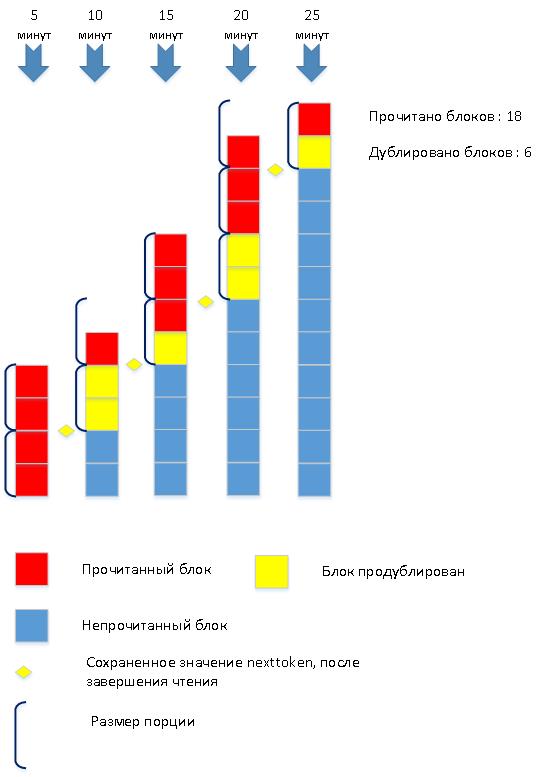
Как обычно, оптимальное решение-посредине.
Размер порции минимальный, но в процессе чтения, размер можно увеличивать, для сокращения числа чтений.
Нужно отметить, что полностью задача подбора оптимального размера считываемой порции пока не решена и требует более глубокой проработки и анализа. Может, быть, чуть позже.
Общее описание реализации
Используемые сервисные таблицы
CREATE TABLE endpoint
(
id SERIAL ,
host text
);
TABLE database
(
id SERIAL ,
…
last_aws_log_time text ,
last_aws_nexttoken text ,
aws_max_item_size integer
);
last_aws_log_time - временная метка последнего загруженного лог-файла в формате YYYY-MM-DD-HH24.
last_aws_nexttoken - текстовая метка последней загруженной порции.
aws_max_item_size- эмпирическим путем, подобранный начальный размер порции.
Полный текст скрипта
[download_aws_piece.sh]
#!/bin/bash
# download_aws_piece.sh
# downloan piece of log from AWS
# version HABR
let min_item_size=1024
let max_item_size=1048576
let growth_factor=3
let growth_counter=1
let growth_counter_max=3
echo $(date +%Y%m%d%H%M)': download_aws_piece.sh:''STARTED'
AWS_LOG_TIME=$1
echo $(date +%Y%m%d%H%M)': download_aws_piece.sh:AWS_LOG_TIME='$AWS_LOG_TIME
database_id=$2
echo $(date +%Y%m%d%H%M)': download_aws_piece.sh:database_id='$database_id
RESULT_FILE=$3
endpoint=`psql -h MONITOR_ENDPOINT.rds.amazonaws.com -U USER -d MONITOR_DATABASE_DATABASE -A -t -c "select e.host from endpoint e join database d on e.id = d.endpoint_id where d.id = $database_id "`
echo $(date +%Y%m%d%H%M)': download_aws_piece.sh:endpoint='$endpoint
db_instance=`echo $endpoint | awk -F"." '{print toupper($1)}'`
echo $(date +%Y%m%d%H%M)': download_aws_piece.sh:db_instance='$db_instance
LOG_FILE=$RESULT_FILE'.tmp_log'
TMP_FILE=$LOG_FILE'.tmp'
TMP_MIDDLE=$LOG_FILE'.tmp_mid'
TMP_MIDDLE2=$LOG_FILE'.tmp_mid2'
current_aws_log_time=`psql -h MONITOR_ENDPOINT.rds.amazonaws.com -U USER -d MONITOR_DATABASE -A -t -c "select last_aws_log_time from database where id = $database_id "`
echo $(date +%Y%m%d%H%M)': download_aws_piece.sh:current_aws_log_time='$current_aws_log_time
if [[ $current_aws_log_time != $AWS_LOG_TIME ]];
then
is_new_log='1'
if ! psql -h MONITOR_ENDPOINT.rds.amazonaws.com -U USER -d MONITOR_DATABASE -v ON_ERROR_STOP=1 -A -t -q -c "update database set last_aws_log_time = '$AWS_LOG_TIME' where id = $database_id "
then
echo $(date +%Y%m%d%H%M)': download_aws_piece.sh: FATAL_ERROR - update database set last_aws_log_time .'
exit 1
fi
else
is_new_log='0'
fi
echo $(date +%Y%m%d%H%M)': download_aws_piece.sh:is_new_log='$is_new_log
let last_aws_max_item_size=`psql -h MONITOR_ENDPOINT.rds.amazonaws.com -U USER -d MONITOR_DATABASE -A -t -c "select aws_max_item_size from database where id = $database_id "`
echo $(date +%Y%m%d%H%M)': download_aws_piece.sh: last_aws_max_item_size='$last_aws_max_item_size
let count=1
if [[ $is_new_log == '1' ]];
then
echo $(date +%Y%m%d%H%M)': download_aws_piece.sh: START DOWNLOADING OF NEW AWS LOG'
if ! aws rds download-db-log-file-portion \
--max-items $last_aws_max_item_size \
--region REGION \
--db-instance-identifier $db_instance \
--log-file-name error/postgresql.log.$AWS_LOG_TIME > $LOG_FILE
then
echo $(date +%Y%m%d%H%M)': download_aws_piece.sh: FATAL_ERROR - Could not get log from AWS .'
exit 2
fi
else
next_token=`psql -h MONITOR_ENDPOINT.rds.amazonaws.com -U USER -d MONITOR_DATABASE -v ON_ERROR_STOP=1 -A -t -c "select last_aws_nexttoken from database where id = $database_id "`
if [[ $next_token == '' ]];
then
next_token='0'
fi
echo $(date +%Y%m%d%H%M)': download_aws_piece.sh: CONTINUE DOWNLOADING OF AWS LOG'
if ! aws rds download-db-log-file-portion \
--max-items $last_aws_max_item_size \
--starting-token $next_token \
--region REGION \
--db-instance-identifier $db_instance \
--log-file-name error/postgresql.log.$AWS_LOG_TIME > $LOG_FILE
then
echo $(date +%Y%m%d%H%M)': download_aws_piece.sh: FATAL_ERROR - Could not get log from AWS .'
exit 3
fi
line_count=`cat $LOG_FILE | wc -l`
let lines=$line_count-1
tail -$lines $LOG_FILE > $TMP_MIDDLE
mv -f $TMP_MIDDLE $LOG_FILE
fi
next_token_str=`cat $LOG_FILE | grep NEXTTOKEN`
next_token=`echo $next_token_str | awk -F" " '{ print $2}' `
grep -v NEXTTOKEN $LOG_FILE > $TMP_FILE
if [[ $next_token == '' ]];
then
cp $TMP_FILE $RESULT_FILE
echo $(date +%Y%m%d%H%M)': download_aws_piece.sh: NEXTTOKEN NOT FOUND - FINISH '
rm $LOG_FILE
rm $TMP_FILE
rm $TMP_MIDDLE
rm $TMP_MIDDLE2
exit 0
else
psql -h MONITOR_ENDPOINT.rds.amazonaws.com -U USER -d MONITOR_DATABASE -v ON_ERROR_STOP=1 -A -t -q -c "update database set last_aws_nexttoken = '$next_token' where id = $database_id "
fi
first_str=`tail -1 $TMP_FILE`
line_count=`cat $TMP_FILE | wc -l`
let lines=$line_count-1
head -$lines $TMP_FILE > $RESULT_FILE
###############################################
# MAIN CIRCLE
let count=2
while [[ $next_token != '' ]];
do
echo $(date +%Y%m%d%H%M)': download_aws_piece.sh: count='$count
echo $(date +%Y%m%d%H%M)': download_aws_piece.sh: START DOWNLOADING OF AWS LOG'
if ! aws rds download-db-log-file-portion \
--max-items $last_aws_max_item_size \
--starting-token $next_token \
--region REGION \
--db-instance-identifier $db_instance \
--log-file-name error/postgresql.log.$AWS_LOG_TIME > $LOG_FILE
then
echo $(date +%Y%m%d%H%M)': download_aws_piece.sh: FATAL_ERROR - Could not get log from AWS .'
exit 4
fi
next_token_str=`cat $LOG_FILE | grep NEXTTOKEN`
next_token=`echo $next_token_str | awk -F" " '{ print $2}' `
TMP_FILE=$LOG_FILE'.tmp'
grep -v NEXTTOKEN $LOG_FILE > $TMP_FILE
last_str=`head -1 $TMP_FILE`
if [[ $next_token == '' ]];
then
concat_str=$first_str$last_str
echo $concat_str >> $RESULT_FILE
line_count=`cat $TMP_FILE | wc -l`
let lines=$line_count-1
tail -$lines $TMP_FILE >> $RESULT_FILE
echo $(date +%Y%m%d%H%M)': download_aws_piece.sh: NEXTTOKEN NOT FOUND - FINISH '
rm $LOG_FILE
rm $TMP_FILE
rm $TMP_MIDDLE
rm $TMP_MIDDLE2
exit 0
fi
if [[ $next_token != '' ]];
then
let growth_counter=$growth_counter+1
if [[ $growth_counter -gt $growth_counter_max ]];
then
let last_aws_max_item_size=$last_aws_max_item_size*$growth_factor
let growth_counter=1
fi
if [[ $last_aws_max_item_size -gt $max_item_size ]];
then
let last_aws_max_item_size=$max_item_size
fi
psql -h MONITOR_ENDPOINT.rds.amazonaws.com -U USER -d MONITOR_DATABASE -A -t -q -c "update database set last_aws_nexttoken = '$next_token' where id = $database_id "
concat_str=$first_str$last_str
echo $concat_str >> $RESULT_FILE
line_count=`cat $TMP_FILE | wc -l`
let lines=$line_count-1
#############################
#Get middle of file
head -$lines $TMP_FILE > $TMP_MIDDLE
line_count=`cat $TMP_MIDDLE | wc -l`
let lines=$line_count-1
tail -$lines $TMP_MIDDLE > $TMP_MIDDLE2
cat $TMP_MIDDLE2 >> $RESULT_FILE
first_str=`tail -1 $TMP_FILE`
fi
let count=$count+1
done
#
#################################################################
exit 0
Фрагменты скрипта с некоторыми пояснениями:
Входные параметры скрипта:
- Временная метка имени лог-файла в формате YYYY-MM-DD-HH24: AWS_LOG_TIME=$1
- ID Базы данных: database_id=$2
- Имя собранного лог-файла: RESULT_FILE=$3
current_aws_log_time=`psql -h MONITOR_ENDPOINT.rds.amazonaws.com -U USER -d MONITOR_DATABASE -A -t -c "select last_aws_log_time from database where id = $database_id "`
Если временная метка последнего загруженного лог-файла не совпадает с входным параметром - загружается новый лог-файл:
if [[ $current_aws_log_time != $AWS_LOG_TIME ]];
then
is_new_log='1'
if ! psql -h ENDPOINT.rds.amazonaws.com -U USER -d MONITOR_DATABASE -v ON_ERROR_STOP=1 -A -t -c "update database set last_aws_log_time = '$AWS_LOG_TIME' where id = $database_id "
then
echo '***download_aws_piece.sh -FATAL_ERROR - update database set last_aws_log_time .'
exit 1
fi
else
is_new_log='0'
fi
Получаем значение метки nexttoken из загруженного файла:
next_token_str=`cat $LOG_FILE | grep NEXTTOKEN`
next_token=`echo $next_token_str | awk -F" " '{ print $2}' `
Признаком окончания загрузки служит пустое значение nexttoken.
В цикле считаем порции файла, попутно, сцепляя строки и увеличивая размер порции:
[Главный цикл]
# MAIN CIRCLE
let count=2
while [[ $next_token != '' ]];
do
echo $(date +%Y%m%d%H%M)': download_aws_piece.sh: count='$count
echo $(date +%Y%m%d%H%M)': download_aws_piece.sh: START DOWNLOADING OF AWS LOG'
if ! aws rds download-db-log-file-portion \
--max-items $last_aws_max_item_size \
--starting-token $next_token \
--region REGION \
--db-instance-identifier $db_instance \
--log-file-name error/postgresql.log.$AWS_LOG_TIME > $LOG_FILE
then
echo $(date +%Y%m%d%H%M)': download_aws_piece.sh: FATAL_ERROR - Could not get log from AWS .'
exit 4
fi
next_token_str=`cat $LOG_FILE | grep NEXTTOKEN`
next_token=`echo $next_token_str | awk -F" " '{ print $2}' `
TMP_FILE=$LOG_FILE'.tmp'
grep -v NEXTTOKEN $LOG_FILE > $TMP_FILE
last_str=`head -1 $TMP_FILE`
if [[ $next_token == '' ]];
then
concat_str=$first_str$last_str
echo $concat_str >> $RESULT_FILE
line_count=`cat $TMP_FILE | wc -l`
let lines=$line_count-1
tail -$lines $TMP_FILE >> $RESULT_FILE
echo $(date +%Y%m%d%H%M)': download_aws_piece.sh: NEXTTOKEN NOT FOUND - FINISH '
rm $LOG_FILE
rm $TMP_FILE
rm $TMP_MIDDLE
rm $TMP_MIDDLE2
exit 0
fi
if [[ $next_token != '' ]];
then
let growth_counter=$growth_counter+1
if [[ $growth_counter -gt $growth_counter_max ]];
then
let last_aws_max_item_size=$last_aws_max_item_size*$growth_factor
let growth_counter=1
fi
if [[ $last_aws_max_item_size -gt $max_item_size ]];
then
let last_aws_max_item_size=$max_item_size
fi
psql -h MONITOR_ENDPOINT.rds.amazonaws.com -U USER -d MONITOR_DATABASE -A -t -q -c "update database set last_aws_nexttoken = '$next_token' where id = $database_id "
concat_str=$first_str$last_str
echo $concat_str >> $RESULT_FILE
line_count=`cat $TMP_FILE | wc -l`
let lines=$line_count-1
#############################
#Get middle of file
head -$lines $TMP_FILE > $TMP_MIDDLE
line_count=`cat $TMP_MIDDLE | wc -l`
let lines=$line_count-1
tail -$lines $TMP_MIDDLE > $TMP_MIDDLE2
cat $TMP_MIDDLE2 >> $RESULT_FILE
first_str=`tail -1 $TMP_FILE`
fi
let count=$count+1
done
Продолжение тут - Выгрузка лога PostgreSQL из облака AWS - часть 2.
#postgresql #aws #cloud #bash #scripting #clowdwatch #download-db-log-file-portion