Haskell's evil twin
Думаю, многие из тех, кто знаком с Хаскелем, слышали, что есть еще такой язык Clean, который:
* чистый, ленивый, функциональный,
* знаменит своей эффективностью,
* похож на Хаскель, но
* обходится без монад для ввода-вывода и
* поддерживает изменяемые по месту структуры данных без потери ленивости и referential transparency за счет так называемых уникальных типов.
Я давно хотел познакомиться с ним поближе и прочувствовать что такое программирование с уникальными типами. Оказалось, что это не такое простое занятие (больше всего оно напоминает завязывание шнурков одной рукой), и чтобы написать что-то посложнее hello world'a и факториала нужно набрать определенный уровень навыков и понимания, в процессе пару раз вывихнув мозг. Теперь, когда я таки написал нетривиальную программу на нем (больше 1К строк и со штуками вроде уникальных деревьев из АТД с уникальными массивами), мне кажется, что я кое-что понял и могу поделиться.
Итак, все, что вы не хотели узнать о Clean и даже не думали спросить - под катом.
Синтаксически Clean действительно похож на Хаскель, но есть масса мелких различий (запись списков, list comprehensions, лямбд, типов функций и пр.). Обязательный пример с факториалом:
fac :: Int -> Int
fac 0 = 1
fac n = n * fac (n-1)
или
fac n
| n==0 = 1
| otherwise = n * fac (n-1)
otherwise необязателен, можно просто:
fac n
| n==0 = 1
= n * fac (n-1)
Допустим, нам по работе очень нужно узнать количество простых чисел меньших 5 миллионов. На Хаскеле простое лобовое решение может выглядеть так:
primes = 2:3:[x | x<-[4..], isPrime x]
isPrime x = all (/=0) . map (x `mod`) . takeWhile ((<=x).(^2)) $ primes
main = print $ length $ takeWhile (<=5000000) primes
(подсмотрено у jdevelop)
GHC 6.12 над ним думает около секунды и рожает exe размером 916279 байт, который отрабатывает на моей машине за 9 секунд.
Полный текст аналогичной программы на Clean выглядит так:
module numprimes
import StdEnv
Start = length (takeWhile (\x -> x < 5000000) primes) where
primes = [2:3:[x \\ x<-[4..] | isPrime x]]
isPrime x = ((all ((<>) 0)) o (map ((rem) x)) o (takeWhile (\y = y^2 <= x))) primes
print здесь не нужен, т.к. вычисленное значение Start будет выведено на консоль. Компилируется мгновенно (вообще надо заметить, что компилятор у Clean офигительно быстрый), получается ехе в 63488 байт, который отрабатывает за 11 секунд, половину из которых отнимает сборщик мусора. Приятная черта Clean - маленькие бинарники на выходе. Секрет в том, что большая часть рантайма - сборщики мусора (их там несколько, об этом позже) и часть стандартной библиотеки - написана на ассемблере (и несколько раз: для i386, amd64, power mac и Sun 4).
В предыдущем примере используется list comprehension. Наравне со списками, такой же первоклассной сущностью в Clean выступают массивы, и для них тоже есть comprehensions:
list1 = [1,2,3]
list2 = [2,4..10] // 2,4,6,8,10
list3 = [1..] // 1,2,3...
list4 = [x*10 \\ x <- list3 | x rem 2 == 1] // 10,30,50,70,..
array1 = {1, 2, 3}
array2 = {x*10 \\ x <- list2 | x rem 4 == 0} // 40,80
array3 = {x+y \\ x <-: array1 , y <-: array2} // 41,81,42,82,43,83
array4 = {x*y \\ x <-: array2 & y <- list4} // 400, 2400 i.e. 40*10, 80*30
Если тип списка интов именуется [Int], то тип массива интов - {Int}. Значения в массивах и списках могут быть помечены как строгие (!) или как unboxed(#). Например, unboxed массив Char'ов - это {#Char}. Кстати, именно так в Clean представлены строки: тип String - это синоним для {#Char}.
Раз у нас есть массивы, давайте перепишем пример с простыми числами, поместив их в массив и применив решето Эратосфена.
nprimes n = length [x \\ x <-: arr | x] where
arr :: *{#Bool}
arr = loop {createArray n True & [0] = False, [1] = False} 2
loop a i
| i >= n = a
| a.[i] = loop {a & [j] = False \\ j <- [i*2, i*3 .. N-1]} (i+1)
= loop a (i+1)
createArray n True создает массив из n элементов, заполняя его значениями True.
Изменение i-го элемента массива записывается так: { a & [i] = val }
Соответственно, {createArray n True & [0] = False, [1] = False} создает массив, заполненный True, и записывает в 0-й и 1-й элементы False. Полученный массив мы передаем в локальную функцию - цикл по i, которая по завершению (i >= n) нам его вернет, а пока не завершилась смотрит на i-й элемент массива, и если там истина (т.е. очередное число помечено как простое), то обновляет массив, записав False в элементы i*2, i*3 .. N-1 посредством array comprehension. Главный нюанс в том, что чтобы заниматься такими деструктивными апдейтами массива, он должен быть уникальным. Именно это означает звездочка в типе: *{#Bool} - уникальный unboxed массив Bool'ов.
Что же это такое - уникальное значение? Исходная идея состоит в том, что если в некоторой точке программы у нас есть некий объект (например, массив, запись или файл), и мы уверены в том, что в этот момент на него нигде больше нет других ссылок, то его можно изменить, ничего не испортив. И это будет совершенно чистая операция. В чистом языке у нас нет изменяемых переменных, а есть только именуемые неизменные значения. Если мы вычисляем
x' = f x
и компилятор нам гарантирует, что на х больше нигде нет ссылок, значит в этом месте х использован последний раз, занимаемую им память можно после вычисления f x освободить. А если x' и x одного типа и размера, то вместо объявления х мусором и выделения памяти для x' можно разместить x' там, где был х. Вот мы и получили изменение по месту без нарушения чистоты.
Этот же механизм хорошо подходит для ввода-вывода: если на файл есть только одна ссылка, и операция записи ее съедает, возвращая "новый" файл, то все операции с этим файлом будут естественным образом упорядочены безо всяких монад даже несмотря на ленивость вычислений.
Start world = endworld where
(close_ok, endworld) = fclose f3 world1
(open_ok, f1, world1) = fopen "hello.txt" FWriteText world
f3 = fwrites "world!" f2
f2 = fwrites "hello " f1
world здесь имеет тип *World и обозначает весь этот ваш так называемый реальный мир, данный нам в единственном экземпляре (что бы там ни думал Эверетт), и потому отмеченный звездочкой.
Конечно, давать новое имя переменной после каждой операции с ней не слишком удобно. Поэтому в Clean ввели специальную синтаксичекую конструкцию, называемую let-before и по смыслу похожую на let .. in в окамле:
Start world
# (ok, f, world) = fopen "hello.txt" FWriteText world
# f = fwrites "hello " f
# f = fwrites "world!" f
# (ok, world) = fclose f world
= world
Она позволяет переиспользовать имена: одно и то же имя слева и справа от = здесь означает не рекурсивное определение (как в хаскелевском let .. in и окамловском let rec .. in), а использование ранее определенного значения справа от = и переопределение имени слева от =. Порядок строк становится важным и в целом соответствует порядку вычислений. Такой вот способ писать императивно в чистом ленивом языке.
Теперь попробуем написать функцию, меняющую местами первые два элемента массива. Первая мысль
swap2 a = {a & [0] = a.[1], [1] = a.[0]}
наталкивается на сообщение об ошибке:
Uniqueness error [test.icl,57,swap2]: "a" demanded attribute cannot be offered by shared object
Смысл в том, что мы пытаемся изменять содержимое массива, а значит он должен быть уникальным, но в у нас в одном выражении сразу несколько ссылок на него: a, a.[1] и a.[0]. Попытка вынести обращения за скобки
swap2 a = {a & [0] = y, [1] = x} where
x = a.[0]
y = a.[1]
ничего не меняет, это лишь замена имен без изменения смысла.
Даже let-before нам не поможет:
swap2 a
# x = a.[0]
# y = a.[1]
= {a & [0] = y, [1] = x}
вызывает ту же ошибку. В ленивой модели исполнения x и y - лишь рецепты получить первые элементы массива, а еще не сами элементы, поэтому они содержат ссылки на массив. Вот если бы мы вычисляли строго, то все было бы хорошо: записали бы нужные элементы в x и y, и в конечном выражении лишних ссылок на уникальный массив уже не было бы. Поэтому в язык добавлена еще одна конструкция - строгий let-before:
swap2 a
#! x = a.[0]
#! y = a.[1]
= {a & [0] = y, [1] = x}
Вот так уже компилируется успешно, т.к. x и y вычисляются прежде чем начнет вычисляться выражение с массивом, а потому ссылок на него уже не содержат.
Всегда ли действует такое жесткое ограничение на число ссылок? Вовсе нет. Например, давайте найдем максимум и минимум в уникальном массиве:
fold f a = foldl f a.[0] [x \\ x <-: a]
Start = (fold min a, fold max a, a) where
a :: *{#Int}
a = {createArray 10 0 & [3] = 5}
Такой код успешно компилируется и работает, несмотря на то, что у нас в одном выражении сразу три ссылки на уникальный массив. В этом разница между уникальными типами в Clean и линейными типами из соответствующей теории. Когда компилятор Clean анализирует код функции, он смотрит для каждого значения сколько синтаксически параллельных ссылок на него есть, и какие требования к этому значению предъявляются. Если мы меняем массив или пишем в файл, то мы хотим "право на запись". Такое требование выражается в помечании типа значения атрибутом уникальности. Если мы передаем значение в функцию, требующую уникальное значение (т.е. права на запись), то нам нужно право на запись для передаваемого значения, значит оно тоже помечается как уникальное.
Дальше смотрим, сколько есть параллельных упоминаний значения. Параллельными считаются все множественные упоминания одного значения, кроме альтернативных и observing. Альтернативные - это в разных ветвях/альтернативах функции, например:
f True a = a.[1]
f False a = a.[2]
Поскольку выполняется всегда какая-то одна альтернатива, понятно, что упоминания в разных альтернативах одного значения не опасны, т.к. не создадут одновременных ссылок.
Observing reference - это когда значение участвует в guard'e и в его теле, как в примере выше с решетом Эратосфена, где a.[i] было условием в guard'е, при этом массив "a" менялся в той же ветке. Еще observing - когда участвует в строгом let-before, как в примере выше с swap2 (но есть нюансы, о которых позже). Так вот, если у нас в функции у какого-то значения есть параллельные (не альтернативные и не observing) упоминания, то это грозит одновременно существующими ссылками на один объект, поэтому такое значение называется shared и помечается как read-only. А дальше просто - чтобы не допустить хаоса, нельзя использовать shared/read-only объект там, где требуются права на запись. Но обратное вполне возможно и невозбранно: если у нас есть несколько параллельных упоминаний одного значения, но ни одно из них не требует прав на запись, то его можно расшарить, даже если это изначально уникальный объект. Именно это происходит в
(fold min a, fold max a, a)
Ни одно из упоминаний не требует прав на запись, поэтому сюда можно подставить уникальный массив и иметь на него три ссылки.
Как такие вещи выражаются в системе типов? Уникальность - это атрибут, который навешивается на тип. Сперва происходит обычный вывод типов данных а-ля Хаскель, а потом на выведенные типы сверху навешиваются атрибуты, специфицирующие требования к уникальности. Чтобы обозначить непременное требование уникальности, перед типом ставится звездочка.
swap2 :: *(a b) -> .(a b) | Array a b
(в общем случае массив так хитро обозначается, потому что это type class, ибо например массив интов и unboxed массив интов - разные типы, их объединяет класс Array a Int, к тому же a и b могут иметь разные атрибуты уникальности)
Если значение не может быть уникальным, перед типом ничего не ставится.
two :: a -> .(a,a)
two x = (x,x)
Если значение может быть как уникальным, так и неуникальным, т.е. у нас нет специальных требований, то ставится точка:
identity :: .a -> .a
identity x = x
Она также означает, что справа и слева одно и то же - если слева уникальное, то и справа тоже, и наоборот.
Но могут быть и более сложные случаи. Вот возьмем совершенно невинную функцию - извлечение первого элемента из массива.
first a = a.[0]
Если мы получаем неуникальный массив неуникальных значений, то результат тоже неуникальный, т.к. гарантировать отсутствие других ссылок на первый элемент нельзя. Если мы получаем уникальный массив неуникальных значений, то результат тоже неуникальный. Если мы получаем уникальный массив уникальных значений, то можем вернуть уникальный результат, т.к. других ссылок на массив и первое значение в этот момент не будет, мы вернем единственную. Что же до четвертого варианта - неуникального массива уникальных значений - то он попросту невозможен, т.к. как только у нас есть две разных ссылки на массив, то к элементам можно добраться разными путями, а значит их уникальность потеряна. Это называется uniqueness propagation rule - в сложных типах атрибут уникальности автоматически распространяется изнутри наружу.
Чтобы записать такие непростые условия уникальности для такой простой функции, используются именованные атрибуты и неравенства с ними. Результат выглядит так:
first :: u:(a v:b) -> v:b | Array a b, [u <= v]
first a = a.[0]
Здесь u - переменная для атрибута уникальности массива, v - переменная для атрибута уникальности значений массива. Уникальность результата у нас совпадает с уникальностью элементов массива, поэтому результат помечен той же v. При этом атрибуты массива и его элементов связаны неравенством u <= v, которое можно читать как "число ссылок u не больше числа ссылок v" или "уникальность u следует/диктуется уникальностью v". Т.е. если элементы массива уникальные (на них одна ссылка, v=1), то и сам массив уникальный: u=1. Если же элементы массива неуникальные (v>1), то массив может быть как уникальным, так и нет (u=1 или u>1).
Все это было бы здорово, но есть нюансы. Вот есть у нас код
#! y = f x
# z = g x
В нем два упоминания "х", но они observing: "y" вычисляется строго, и к моменту вычисления "g x" предыдущей ссылки на "х" уже не будет, да? Необязательно. Если "у" - что-то сложное, то внутри него еще могут быть части, ссылающиеся на "х". Поэтому если "у" - одного из базовых типов, или типы "х" и "у" связаны определенным образом, что компилятор может быть уверен в отсутствии ссылок на "х" внутри "у" после его вычисления, то все хорошо. Иначе же такие ссылки считаются параллельными. А значит, если f или g требует уникальности аргумента, такой код не скомпилируется. К сожалению, анализ этот не слишком умный, и часто принимает неверное, перестраховочное решение. И на практике это происходит очень часто. Поэтому очень часто такой код превращается в
#! (y,x) = f x
# z = g x
При этом приходится менять определение f, чтобы она возвращала вместе с результатом еще и аргумент, даже если она сама его не меняет. Но это может привести к тому, что внутри f возникнут похожие сложности с уникальностью, и придется не просто возвращать аргумент, а строить его копию. Примеры будут в последующих постах.
Помимо всей этой ботвы с уникальностью в языке есть много других интересных вещей, вроде богатой системы классов типов (в том числе multiparameter и higher-order), generics для работы с произвольными типами, всяких existentials, поддержки динамических типов, простых макросов, но я об этом всем сейчас не буду рассказывать, это все есть и в Хаскеле в том или ином виде.
Виндовым пользователям Clean доступен сразу в виде CleanIDE:
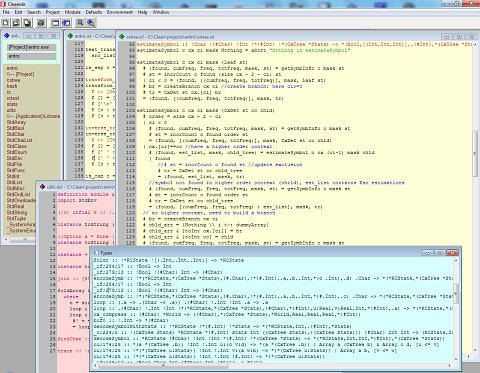
Поначалу она кажется неудобной, но быстро привыкаешь и даже начинаешь ценить. Даже разный цвет фона для разных типов файлов кажется хорошей и удобной идеей (в Clean каждый модуль кроме главного представлен двумя файлами - definition, как .h или .mli, и implementation, как .c или .ml, переключаться между ними можно быстро по хоткею). Довольно удобна фича, когда после компиляции выскакивает окошко со всеми выведенными типами, откуда можно нужные скопипастить и вставить в свой текст. Есть толковый профайлер, который может показать какие функции сколько времени работали, сколько раз вызывались и как (строго, лениво, каррировано) и сколько памяти навыделяли. Сам компилятор, который вызывается автоматически из IDE, - консольное приложение, но совершенно недокументированное, как им пользоваться без IDE - непонятно.
Исходный код написанный на самом Clean'e компилятор сперва превращает в ассемблер/байткод ABC-машины. Он универсальный для всех платформ. Из этого представления другой модуль, написанный уже на Си, генерит машинный код целевой платформы. Как я уже упоминал, сборщики мусора и многие примитивы написаны на ассемблере. Это особенно весело, когда становится единственной документацией. Например, для строк определен оператор %, который позволяет получить подстроку. Смысл его аргументов нигде не документирован, а исходник состоит из вызова примитива на ассемблере, понять который может только автор. :) Аналогично со сборщиками мусора. В опциях IDE есть галочка "Use Marking Garbage Collector". Суть ее нигде не документирована и не объяснена. Но из изучения исходников и обрывочных объяснений авторов в мейллисте, вырисовывается такая картина. По умолчанию используется простейший copying garbage collector, работающий по алгоритму Cheney: вся имеющаяся куча делится пополам, память выделяется в одной половине, когда она заканчивается, все живые объекты копируются в другую половину и теперь используется она. Максимальный размер кучи задается в настройках проекта. Если, скажем, указать там 512М, то программа сразу выделит себе 512 мегов, из которых реально будет использовать лишь 256, но в системе будет съедено все 512, даже если живых данных совсем немного. Если этих 256 мегов не хватит, программа завершится с сообщеннием Heap full. Второй сборщик мусора, который включается той галочкой, работает иначе. С ним используется вся доступная куча целиком, а когда место в ней кончается, сборщик маркирует живые объекты и передвигает их ближе к началу (compacting). Поэтому получается доступно больше памяти под данные, но работает такой вариант (когда данных много) заметно медленнее. Кроме кучи отдельно выделяется место под стек, размер которого также фиксирован и задается в настройках проекта.
Скомпилированный код эмулирует поведение ABC-машины. Называется она так в честь трех стеков: стек A содержит указатели на узлы в куче, стек B - значения Basic types (Int, Bool, Real, Char), а стек С - это Control стек, в нем указатели на адреса возврата. На практике последние два объединены в один, поэтому есть два стека - А и ВС - которые растут навстречу друг другу внутри фиксированного региона. Узлы в куче содержат указатели на дескрипторы, их описывающие, и указатели на другие узлы. Рядом (или вместо?) с дескриптором узла лежит укатель на код, вычисляющий его значение, оперируя стеками АВС. Соответсвтенно, ленивое значение - это укзатель на узел в куче, чтобы его вычислить его данные кладутся на стеки (указатели на А, простые значения на ВС), после чего вызывается код вычисления узла из ссылки в самом узле. Когда такой узел вычислен, он перезаписывается вычисленным значением.
В литературе язык иногда называется Concurrent Clean, а в статьях и книгах описывается абстрактная машина PABC - Parallel то бишь. Забудьте, все это в прошлом. Сейчас все строго в один поток, параллелизма нет вообще никакого.
Рантайм статически линкуется в получаемый бинарник. При этом лицензия на него двойная - LGPL и коммерческая. Значит, бинарники можно распространять либо с исходниками под той же LGPL, либо купив коммерческую лицензию. Последняя доступна в двух вариантах. Первый стоит 75 евро, но требует ежегодных отчислений royalty, размер которых нужно оговаривать отдельно. Второй без роялти, но цена договорная. Следующую версию обещают выпустить под BSD лицензией, но это еще когда будет.
Ах, да. Книги и community. Книг нормальных полторы штуки - Functional Programming in CLEAN от авторов и Language Report - спецификация. Есть старинная книжка Plasmeijer'a - Functional Programming and Parallel Graph Rewriting про внутреннее устройство, но она сильно устарела, по сути там вообще другой язык. Есть еще книжка Programming in Clean от Philippos Apolinario, но это знаете, есть такой жанр "дети рисуют для детей": очень наивно и с кучей ошибок. Что до community, то его просто нет. Есть mail list, но мертвый - на 99% состоит из calls for participation всяких конференций. Библиотек, значится, тоже практически никаких нет (а стандартная библиотека очень минималистична). Ну и отдельно можно поблагодарить авторов за отличное название языка: нагуглить что-либо по нему практически невозможно.
* чистый, ленивый, функциональный,
* знаменит своей эффективностью,
* похож на Хаскель, но
* обходится без монад для ввода-вывода и
* поддерживает изменяемые по месту структуры данных без потери ленивости и referential transparency за счет так называемых уникальных типов.
Я давно хотел познакомиться с ним поближе и прочувствовать что такое программирование с уникальными типами. Оказалось, что это не такое простое занятие (больше всего оно напоминает завязывание шнурков одной рукой), и чтобы написать что-то посложнее hello world'a и факториала нужно набрать определенный уровень навыков и понимания, в процессе пару раз вывихнув мозг. Теперь, когда я таки написал нетривиальную программу на нем (больше 1К строк и со штуками вроде уникальных деревьев из АТД с уникальными массивами), мне кажется, что я кое-что понял и могу поделиться.
Итак, все, что вы не хотели узнать о Clean и даже не думали спросить - под катом.
Синтаксически Clean действительно похож на Хаскель, но есть масса мелких различий (запись списков, list comprehensions, лямбд, типов функций и пр.). Обязательный пример с факториалом:
fac :: Int -> Int
fac 0 = 1
fac n = n * fac (n-1)
или
fac n
| n==0 = 1
| otherwise = n * fac (n-1)
otherwise необязателен, можно просто:
fac n
| n==0 = 1
= n * fac (n-1)
Допустим, нам по работе очень нужно узнать количество простых чисел меньших 5 миллионов. На Хаскеле простое лобовое решение может выглядеть так:
primes = 2:3:[x | x<-[4..], isPrime x]
isPrime x = all (/=0) . map (x `mod`) . takeWhile ((<=x).(^2)) $ primes
main = print $ length $ takeWhile (<=5000000) primes
(подсмотрено у jdevelop)
GHC 6.12 над ним думает около секунды и рожает exe размером 916279 байт, который отрабатывает на моей машине за 9 секунд.
Полный текст аналогичной программы на Clean выглядит так:
module numprimes
import StdEnv
Start = length (takeWhile (\x -> x < 5000000) primes) where
primes = [2:3:[x \\ x<-[4..] | isPrime x]]
isPrime x = ((all ((<>) 0)) o (map ((rem) x)) o (takeWhile (\y = y^2 <= x))) primes
print здесь не нужен, т.к. вычисленное значение Start будет выведено на консоль. Компилируется мгновенно (вообще надо заметить, что компилятор у Clean офигительно быстрый), получается ехе в 63488 байт, который отрабатывает за 11 секунд, половину из которых отнимает сборщик мусора. Приятная черта Clean - маленькие бинарники на выходе. Секрет в том, что большая часть рантайма - сборщики мусора (их там несколько, об этом позже) и часть стандартной библиотеки - написана на ассемблере (и несколько раз: для i386, amd64, power mac и Sun 4).
В предыдущем примере используется list comprehension. Наравне со списками, такой же первоклассной сущностью в Clean выступают массивы, и для них тоже есть comprehensions:
list1 = [1,2,3]
list2 = [2,4..10] // 2,4,6,8,10
list3 = [1..] // 1,2,3...
list4 = [x*10 \\ x <- list3 | x rem 2 == 1] // 10,30,50,70,..
array1 = {1, 2, 3}
array2 = {x*10 \\ x <- list2 | x rem 4 == 0} // 40,80
array3 = {x+y \\ x <-: array1 , y <-: array2} // 41,81,42,82,43,83
array4 = {x*y \\ x <-: array2 & y <- list4} // 400, 2400 i.e. 40*10, 80*30
Если тип списка интов именуется [Int], то тип массива интов - {Int}. Значения в массивах и списках могут быть помечены как строгие (!) или как unboxed(#). Например, unboxed массив Char'ов - это {#Char}. Кстати, именно так в Clean представлены строки: тип String - это синоним для {#Char}.
Раз у нас есть массивы, давайте перепишем пример с простыми числами, поместив их в массив и применив решето Эратосфена.
nprimes n = length [x \\ x <-: arr | x] where
arr :: *{#Bool}
arr = loop {createArray n True & [0] = False, [1] = False} 2
loop a i
| i >= n = a
| a.[i] = loop {a & [j] = False \\ j <- [i*2, i*3 .. N-1]} (i+1)
= loop a (i+1)
createArray n True создает массив из n элементов, заполняя его значениями True.
Изменение i-го элемента массива записывается так: { a & [i] = val }
Соответственно, {createArray n True & [0] = False, [1] = False} создает массив, заполненный True, и записывает в 0-й и 1-й элементы False. Полученный массив мы передаем в локальную функцию - цикл по i, которая по завершению (i >= n) нам его вернет, а пока не завершилась смотрит на i-й элемент массива, и если там истина (т.е. очередное число помечено как простое), то обновляет массив, записав False в элементы i*2, i*3 .. N-1 посредством array comprehension. Главный нюанс в том, что чтобы заниматься такими деструктивными апдейтами массива, он должен быть уникальным. Именно это означает звездочка в типе: *{#Bool} - уникальный unboxed массив Bool'ов.
Что же это такое - уникальное значение? Исходная идея состоит в том, что если в некоторой точке программы у нас есть некий объект (например, массив, запись или файл), и мы уверены в том, что в этот момент на него нигде больше нет других ссылок, то его можно изменить, ничего не испортив. И это будет совершенно чистая операция. В чистом языке у нас нет изменяемых переменных, а есть только именуемые неизменные значения. Если мы вычисляем
x' = f x
и компилятор нам гарантирует, что на х больше нигде нет ссылок, значит в этом месте х использован последний раз, занимаемую им память можно после вычисления f x освободить. А если x' и x одного типа и размера, то вместо объявления х мусором и выделения памяти для x' можно разместить x' там, где был х. Вот мы и получили изменение по месту без нарушения чистоты.
Этот же механизм хорошо подходит для ввода-вывода: если на файл есть только одна ссылка, и операция записи ее съедает, возвращая "новый" файл, то все операции с этим файлом будут естественным образом упорядочены безо всяких монад даже несмотря на ленивость вычислений.
Start world = endworld where
(close_ok, endworld) = fclose f3 world1
(open_ok, f1, world1) = fopen "hello.txt" FWriteText world
f3 = fwrites "world!" f2
f2 = fwrites "hello " f1
world здесь имеет тип *World и обозначает весь этот ваш так называемый реальный мир, данный нам в единственном экземпляре (что бы там ни думал Эверетт), и потому отмеченный звездочкой.
Конечно, давать новое имя переменной после каждой операции с ней не слишком удобно. Поэтому в Clean ввели специальную синтаксичекую конструкцию, называемую let-before и по смыслу похожую на let .. in в окамле:
Start world
# (ok, f, world) = fopen "hello.txt" FWriteText world
# f = fwrites "hello " f
# f = fwrites "world!" f
# (ok, world) = fclose f world
= world
Она позволяет переиспользовать имена: одно и то же имя слева и справа от = здесь означает не рекурсивное определение (как в хаскелевском let .. in и окамловском let rec .. in), а использование ранее определенного значения справа от = и переопределение имени слева от =. Порядок строк становится важным и в целом соответствует порядку вычислений. Такой вот способ писать императивно в чистом ленивом языке.
Теперь попробуем написать функцию, меняющую местами первые два элемента массива. Первая мысль
swap2 a = {a & [0] = a.[1], [1] = a.[0]}
наталкивается на сообщение об ошибке:
Uniqueness error [test.icl,57,swap2]: "a" demanded attribute cannot be offered by shared object
Смысл в том, что мы пытаемся изменять содержимое массива, а значит он должен быть уникальным, но в у нас в одном выражении сразу несколько ссылок на него: a, a.[1] и a.[0]. Попытка вынести обращения за скобки
swap2 a = {a & [0] = y, [1] = x} where
x = a.[0]
y = a.[1]
ничего не меняет, это лишь замена имен без изменения смысла.
Даже let-before нам не поможет:
swap2 a
# x = a.[0]
# y = a.[1]
= {a & [0] = y, [1] = x}
вызывает ту же ошибку. В ленивой модели исполнения x и y - лишь рецепты получить первые элементы массива, а еще не сами элементы, поэтому они содержат ссылки на массив. Вот если бы мы вычисляли строго, то все было бы хорошо: записали бы нужные элементы в x и y, и в конечном выражении лишних ссылок на уникальный массив уже не было бы. Поэтому в язык добавлена еще одна конструкция - строгий let-before:
swap2 a
#! x = a.[0]
#! y = a.[1]
= {a & [0] = y, [1] = x}
Вот так уже компилируется успешно, т.к. x и y вычисляются прежде чем начнет вычисляться выражение с массивом, а потому ссылок на него уже не содержат.
Всегда ли действует такое жесткое ограничение на число ссылок? Вовсе нет. Например, давайте найдем максимум и минимум в уникальном массиве:
fold f a = foldl f a.[0] [x \\ x <-: a]
Start = (fold min a, fold max a, a) where
a :: *{#Int}
a = {createArray 10 0 & [3] = 5}
Такой код успешно компилируется и работает, несмотря на то, что у нас в одном выражении сразу три ссылки на уникальный массив. В этом разница между уникальными типами в Clean и линейными типами из соответствующей теории. Когда компилятор Clean анализирует код функции, он смотрит для каждого значения сколько синтаксически параллельных ссылок на него есть, и какие требования к этому значению предъявляются. Если мы меняем массив или пишем в файл, то мы хотим "право на запись". Такое требование выражается в помечании типа значения атрибутом уникальности. Если мы передаем значение в функцию, требующую уникальное значение (т.е. права на запись), то нам нужно право на запись для передаваемого значения, значит оно тоже помечается как уникальное.
Дальше смотрим, сколько есть параллельных упоминаний значения. Параллельными считаются все множественные упоминания одного значения, кроме альтернативных и observing. Альтернативные - это в разных ветвях/альтернативах функции, например:
f True a = a.[1]
f False a = a.[2]
Поскольку выполняется всегда какая-то одна альтернатива, понятно, что упоминания в разных альтернативах одного значения не опасны, т.к. не создадут одновременных ссылок.
Observing reference - это когда значение участвует в guard'e и в его теле, как в примере выше с решетом Эратосфена, где a.[i] было условием в guard'е, при этом массив "a" менялся в той же ветке. Еще observing - когда участвует в строгом let-before, как в примере выше с swap2 (но есть нюансы, о которых позже). Так вот, если у нас в функции у какого-то значения есть параллельные (не альтернативные и не observing) упоминания, то это грозит одновременно существующими ссылками на один объект, поэтому такое значение называется shared и помечается как read-only. А дальше просто - чтобы не допустить хаоса, нельзя использовать shared/read-only объект там, где требуются права на запись. Но обратное вполне возможно и невозбранно: если у нас есть несколько параллельных упоминаний одного значения, но ни одно из них не требует прав на запись, то его можно расшарить, даже если это изначально уникальный объект. Именно это происходит в
(fold min a, fold max a, a)
Ни одно из упоминаний не требует прав на запись, поэтому сюда можно подставить уникальный массив и иметь на него три ссылки.
Как такие вещи выражаются в системе типов? Уникальность - это атрибут, который навешивается на тип. Сперва происходит обычный вывод типов данных а-ля Хаскель, а потом на выведенные типы сверху навешиваются атрибуты, специфицирующие требования к уникальности. Чтобы обозначить непременное требование уникальности, перед типом ставится звездочка.
swap2 :: *(a b) -> .(a b) | Array a b
(в общем случае массив так хитро обозначается, потому что это type class, ибо например массив интов и unboxed массив интов - разные типы, их объединяет класс Array a Int, к тому же a и b могут иметь разные атрибуты уникальности)
Если значение не может быть уникальным, перед типом ничего не ставится.
two :: a -> .(a,a)
two x = (x,x)
Если значение может быть как уникальным, так и неуникальным, т.е. у нас нет специальных требований, то ставится точка:
identity :: .a -> .a
identity x = x
Она также означает, что справа и слева одно и то же - если слева уникальное, то и справа тоже, и наоборот.
Но могут быть и более сложные случаи. Вот возьмем совершенно невинную функцию - извлечение первого элемента из массива.
first a = a.[0]
Если мы получаем неуникальный массив неуникальных значений, то результат тоже неуникальный, т.к. гарантировать отсутствие других ссылок на первый элемент нельзя. Если мы получаем уникальный массив неуникальных значений, то результат тоже неуникальный. Если мы получаем уникальный массив уникальных значений, то можем вернуть уникальный результат, т.к. других ссылок на массив и первое значение в этот момент не будет, мы вернем единственную. Что же до четвертого варианта - неуникального массива уникальных значений - то он попросту невозможен, т.к. как только у нас есть две разных ссылки на массив, то к элементам можно добраться разными путями, а значит их уникальность потеряна. Это называется uniqueness propagation rule - в сложных типах атрибут уникальности автоматически распространяется изнутри наружу.
Чтобы записать такие непростые условия уникальности для такой простой функции, используются именованные атрибуты и неравенства с ними. Результат выглядит так:
first :: u:(a v:b) -> v:b | Array a b, [u <= v]
first a = a.[0]
Здесь u - переменная для атрибута уникальности массива, v - переменная для атрибута уникальности значений массива. Уникальность результата у нас совпадает с уникальностью элементов массива, поэтому результат помечен той же v. При этом атрибуты массива и его элементов связаны неравенством u <= v, которое можно читать как "число ссылок u не больше числа ссылок v" или "уникальность u следует/диктуется уникальностью v". Т.е. если элементы массива уникальные (на них одна ссылка, v=1), то и сам массив уникальный: u=1. Если же элементы массива неуникальные (v>1), то массив может быть как уникальным, так и нет (u=1 или u>1).
Все это было бы здорово, но есть нюансы. Вот есть у нас код
#! y = f x
# z = g x
В нем два упоминания "х", но они observing: "y" вычисляется строго, и к моменту вычисления "g x" предыдущей ссылки на "х" уже не будет, да? Необязательно. Если "у" - что-то сложное, то внутри него еще могут быть части, ссылающиеся на "х". Поэтому если "у" - одного из базовых типов, или типы "х" и "у" связаны определенным образом, что компилятор может быть уверен в отсутствии ссылок на "х" внутри "у" после его вычисления, то все хорошо. Иначе же такие ссылки считаются параллельными. А значит, если f или g требует уникальности аргумента, такой код не скомпилируется. К сожалению, анализ этот не слишком умный, и часто принимает неверное, перестраховочное решение. И на практике это происходит очень часто. Поэтому очень часто такой код превращается в
#! (y,x) = f x
# z = g x
При этом приходится менять определение f, чтобы она возвращала вместе с результатом еще и аргумент, даже если она сама его не меняет. Но это может привести к тому, что внутри f возникнут похожие сложности с уникальностью, и придется не просто возвращать аргумент, а строить его копию. Примеры будут в последующих постах.
Помимо всей этой ботвы с уникальностью в языке есть много других интересных вещей, вроде богатой системы классов типов (в том числе multiparameter и higher-order), generics для работы с произвольными типами, всяких existentials, поддержки динамических типов, простых макросов, но я об этом всем сейчас не буду рассказывать, это все есть и в Хаскеле в том или ином виде.
Виндовым пользователям Clean доступен сразу в виде CleanIDE:

Поначалу она кажется неудобной, но быстро привыкаешь и даже начинаешь ценить. Даже разный цвет фона для разных типов файлов кажется хорошей и удобной идеей (в Clean каждый модуль кроме главного представлен двумя файлами - definition, как .h или .mli, и implementation, как .c или .ml, переключаться между ними можно быстро по хоткею). Довольно удобна фича, когда после компиляции выскакивает окошко со всеми выведенными типами, откуда можно нужные скопипастить и вставить в свой текст. Есть толковый профайлер, который может показать какие функции сколько времени работали, сколько раз вызывались и как (строго, лениво, каррировано) и сколько памяти навыделяли. Сам компилятор, который вызывается автоматически из IDE, - консольное приложение, но совершенно недокументированное, как им пользоваться без IDE - непонятно.
Исходный код написанный на самом Clean'e компилятор сперва превращает в ассемблер/байткод ABC-машины. Он универсальный для всех платформ. Из этого представления другой модуль, написанный уже на Си, генерит машинный код целевой платформы. Как я уже упоминал, сборщики мусора и многие примитивы написаны на ассемблере. Это особенно весело, когда становится единственной документацией. Например, для строк определен оператор %, который позволяет получить подстроку. Смысл его аргументов нигде не документирован, а исходник состоит из вызова примитива на ассемблере, понять который может только автор. :) Аналогично со сборщиками мусора. В опциях IDE есть галочка "Use Marking Garbage Collector". Суть ее нигде не документирована и не объяснена. Но из изучения исходников и обрывочных объяснений авторов в мейллисте, вырисовывается такая картина. По умолчанию используется простейший copying garbage collector, работающий по алгоритму Cheney: вся имеющаяся куча делится пополам, память выделяется в одной половине, когда она заканчивается, все живые объекты копируются в другую половину и теперь используется она. Максимальный размер кучи задается в настройках проекта. Если, скажем, указать там 512М, то программа сразу выделит себе 512 мегов, из которых реально будет использовать лишь 256, но в системе будет съедено все 512, даже если живых данных совсем немного. Если этих 256 мегов не хватит, программа завершится с сообщеннием Heap full. Второй сборщик мусора, который включается той галочкой, работает иначе. С ним используется вся доступная куча целиком, а когда место в ней кончается, сборщик маркирует живые объекты и передвигает их ближе к началу (compacting). Поэтому получается доступно больше памяти под данные, но работает такой вариант (когда данных много) заметно медленнее. Кроме кучи отдельно выделяется место под стек, размер которого также фиксирован и задается в настройках проекта.
Скомпилированный код эмулирует поведение ABC-машины. Называется она так в честь трех стеков: стек A содержит указатели на узлы в куче, стек B - значения Basic types (Int, Bool, Real, Char), а стек С - это Control стек, в нем указатели на адреса возврата. На практике последние два объединены в один, поэтому есть два стека - А и ВС - которые растут навстречу друг другу внутри фиксированного региона. Узлы в куче содержат указатели на дескрипторы, их описывающие, и указатели на другие узлы. Рядом (или вместо?) с дескриптором узла лежит укатель на код, вычисляющий его значение, оперируя стеками АВС. Соответсвтенно, ленивое значение - это укзатель на узел в куче, чтобы его вычислить его данные кладутся на стеки (указатели на А, простые значения на ВС), после чего вызывается код вычисления узла из ссылки в самом узле. Когда такой узел вычислен, он перезаписывается вычисленным значением.
В литературе язык иногда называется Concurrent Clean, а в статьях и книгах описывается абстрактная машина PABC - Parallel то бишь. Забудьте, все это в прошлом. Сейчас все строго в один поток, параллелизма нет вообще никакого.
Рантайм статически линкуется в получаемый бинарник. При этом лицензия на него двойная - LGPL и коммерческая. Значит, бинарники можно распространять либо с исходниками под той же LGPL, либо купив коммерческую лицензию. Последняя доступна в двух вариантах. Первый стоит 75 евро, но требует ежегодных отчислений royalty, размер которых нужно оговаривать отдельно. Второй без роялти, но цена договорная. Следующую версию обещают выпустить под BSD лицензией, но это еще когда будет.
Ах, да. Книги и community. Книг нормальных полторы штуки - Functional Programming in CLEAN от авторов и Language Report - спецификация. Есть старинная книжка Plasmeijer'a - Functional Programming and Parallel Graph Rewriting про внутреннее устройство, но она сильно устарела, по сути там вообще другой язык. Есть еще книжка Programming in Clean от Philippos Apolinario, но это знаете, есть такой жанр "дети рисуют для детей": очень наивно и с кучей ошибок. Что до community, то его просто нет. Есть mail list, но мертвый - на 99% состоит из calls for participation всяких конференций. Библиотек, значится, тоже практически никаких нет (а стандартная библиотека очень минималистична). Ну и отдельно можно поблагодарить авторов за отличное название языка: нагуглить что-либо по нему практически невозможно.